How Rolling and Rollback Deployments work in Kubernetes
Kubernetes has been used heavily on production for the past few years. It offers a plethora of solutions for orchestrating your containers using its declarative API. One of the prominent feature of Kubernetes is its resilience with the ability to perform Rolling and Rollback Deployments.
Primer
Deployments
Deployment is one of the mechanisms for handling workloads (applications) in Kubernetes. It is managed by Kubernetes Deployment Controller.
In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state.
In case of deployment here, the desired state we want to achieve is for the pods. Everything is declarative in K8s, so the desired state is written as a spec in Deployment manifest file.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80If any of our pod instances should fail or update(a status change), the Kubernetes system responds to the difference between manifest spec and status by making a correction, i.e. matching the state of Deployment as defined on the spec.
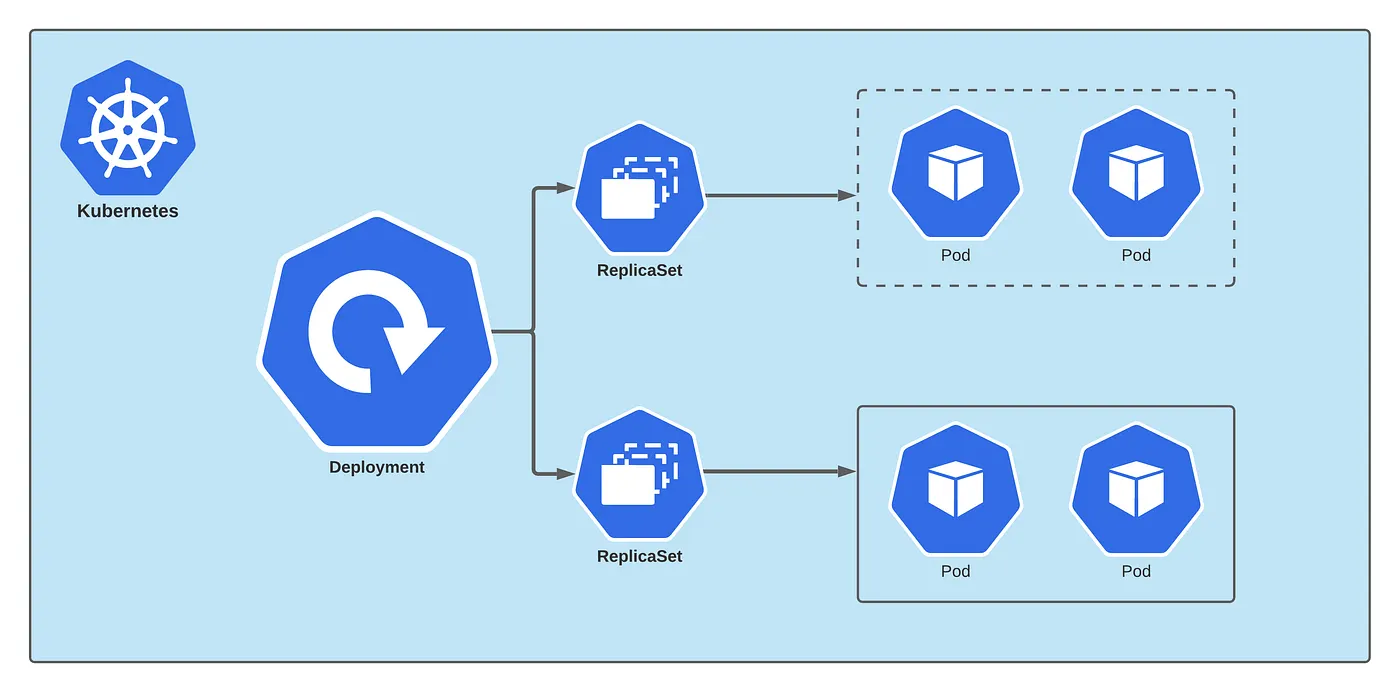
Deployment under the hood
Deployment is an abstraction over ReplicaSet. Under the hood, Deployment creates a ReplicaSet which in turn creates pods on our cluster. As per the name, ReplicaSet is used for managing the replicas of our pods.
In summary, Controller reads the Deployment spec, forwards the pod configuration to ReplicaSet and then it creates the pods with proper replicas.

Rolling Deployment
Kubernetes promises zero down time and one of the reasons behind it is Rolling Deployments. With Rolling Deployments, Kubernetes makes sure that the traffic to the pods are not interrupted when updated pods are being deployed.
Rollback Deployment
Rollback Deployment means, going back to the previous instance of the deployment if there is some issue with the current deployment.
Hands on 🙌
Let’s get our hands-on with Kubernetes and see how these deployment strategies are carried out.
Setup KinD
We will setup a single node Kubernetes cluster on our local machine using KinD (Kubernetes in Docker). Make sure you have Docker running.
We will create a K8s cluster using:
$ kind create clusterWith our cluster ready we are ready for Deployments.
For the purpose of this tutorial, we won’t be touching any YAML files and will be fully utilizing the power of kubectl CLI tool.
Create Deployment
Let’s create our first Deployment using thenginx image.
$ kubectl create deployment test-nginx --image=nginx:1.18-alpineLike mentioned earlier, a Deployment creates a ReplicaSet followed by Pods. You can check these newly created resources using:
$ kubectl get deploy,rs,po -l app=test-nginx
You can check to make sure the Replicaset was created by our Deployment using:
$ kubectl describe rs <replica-set-name>
You can do the same with Pods:
$ kubectl describe po <pod-name> Scale Deployment
Let’s scale the deployment to have 3 instances of nginx pods.
$ kubectl scale deploy test-nginx --replicas=3
Now that we have significant number of pods on our cluster. Let’s try out the Deployment strategies.
Hands-on: Rolling Update Deployment 🍥⏩
Let’s say you were having some issues with v18 of nginx and the v19 fixes it for you. You need to rollout a new update of nginx image to your pod.
By updating the image of the current pods (state change), Kubernetes will rollout a new Deployment.
$ kubectl set image deploy test-nginx nginx=nginx:1.19-alpineAfter we set the new image, we can see the old pods getting terminated and new pods getting created.

We can see Kubernetes at work, making sure the pods are maintained properly. The last of the old pod doesn’t get terminated until the complete replicas for the new pods are created. The old pods also have a grace period which makes sure the traffic it is serving isn’t disconnected for certain time until the requests can be safely routed to the newly created pods.
We successfully updated all our pods to use nginx v19.
$ kubectl describe deploy test-nginx
Hands-on: Rollback Deployment 🍥⏪
Let’s assume the new nginx update has even more problems than the last one and now you realized how blissful life was with the old version. Time for a rollback to the previous version of nginx.
But how do we do that? You might have noticed that there are now two ReplicaSets. It’s due to the same Deployment pattern we discussed earlier, we update our Deployment, it creates a new ReplicaSet which creates new Pods. Kubernetes holds history of up to 10 ReplicaSet by default, we can update that figure by using revisionHistoryLimit on our Deployment spec.
These history are tracked as rollouts. Only the latest rollout is active.
By now, we have made two changes to our Deployment test-nginx so the rollout history should be two.
$ kubectl get rs $ kubectl rollout history deploy test-nginx$ kubectl rollout history deploy test-nginx --revision=1

Alright let’s get to rolling back our update to the previous rollout. We want to rollback to the stage where we were using nginx v18 which is rollout Revision 1.
$ kubectl rollout undo deploy test-nginx --to-revision=1
Like the Rolling Update Deployment, the Rollback Deployment terminates the current pods and replaces them with the pods containing the spec from Revision 1.
If you check the rollout history once again, you can see that the Revision 1 has been used to create the latest pods tagging it with Revision 3. There is no point in maintaining the same spec repeated for multiple revisions, so Kubernetes removes the Revision 1 since we have the latest Revision 3 of the same spec.

Now we are back on the nginx v18. with the Rollback Deployment. You can check that out by:
$ kubectl describe deploy test-nginx
Conclusion 🚀
Kubernetes makes it easy to control the Deployment of our applications with these strategies. This was just a rundown of how Rolling and Rollback Update Deployments work from a ground level. In real-life, we rarely do all these steps manually, since we hand it down to our CI/CD pipeline like ArgoCD.
Thank you for reading. Hope this guide has been helpful for you to understand how Rolling and Rollback Deployments work in Kubernetes. If you have any corrections, suggestions, or feedback feel free to DM me on Twitter or comment down below.
